2024. 8. 14. 12:00ㆍ머신러닝&딥러닝/생성모델
본 논문은 OpenAI에서 발표한, unconditional image generation만 가능했던 디퓨전 계열 아키텍처에 최초로 컨디셔닝을 적용한 논문이다. 이를 Classifier Guidance라고 한다.
Introduction
DDPM이 등장하였지만, 아직까지 이미지 생성의 많은 task의 SOTA는 GAN이 가지고 있었다. 하지만 Diffusion이 GAN에 비해 좋은 성능을 보이는 부분들도 있었다. GAN은 디퓨전에 비해 diversity가 적은데, IS, FID, Prec 등은 이를 반영하지 않는다. 또한, GAN은 하이퍼파라미터를 제대로 설정하지 않으면 쉽게 collapse한다.
저자들은 GAN과 디퓨전의 이러한 성능차이는 두 가지에서 온다고 가설을 세웠다.
- GAN은 divesity - fidelity trade off 가 생긴다. 즉, 다양성이 낮은 만큼 이미지 퀄이 좋은 모델이다.
- 최근 GAN 아키텍처는 어마어마한 성능개선이 많이 이루어졌다. (StyleGAN 등등..)
그래서 이 두 가지를 Diffusion으로 가져오기로 마음먹는다.
- Diffusion의 diversity를 낮추면, 즉 클래스 유도를 하면 fidelity가 높아지지 않을까?
- Diffusion도 아키텍처 개선을 해보자!
따라서 본 논문에서는 이 두 가지를 두 섹션에 나누어 소개한다.
- 디퓨전에 classifier를 붙여서, guidance를 줄 수 있는 Classifier Guidance(CG) : Section 4
- FID를 개선할 수 있는 간단한 아키텍처 개선 : Section 3
Section 2에서는 DDPM(Ho et al.) 원리에 대한 background인데, 이미 다른 포스팅에서 충분히 다루었으므로 본 포스팅에서 Section 2는 생략하기로 한다.
Section 3 : Architecture 개선 사항
- Depth를 Width에 비해 늘리자. (모델 사이즈를 유지한 채)
- Attention head의 수를 늘리자.
- Attention head가 쓰이는 위치를 늘리자. (기존에는 16x16에서만 쓰였으나 32x32, 16x16, 8x8 모두에 쓰기로)
- BigGAN의 residual block을 사용하자.
- Residual connection을 루트2배로 rescaling하자.

먼저, attention head 에 대한 ablation study이다. head 수가 늘어날수록, head 당 채널 수가 줄어들수록 FID가 개선되었다.
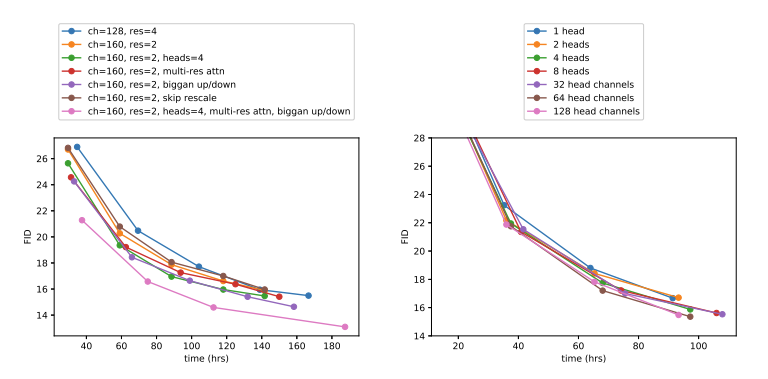
다음으로, 아키텍처 개선에 대한 ablation study이다. 각 사항이 반영되었을 때 시간에 따른 FID 효율을 나타내었다. 깊은 depth, 늘어난 attention head의 위치와 개수, 그리고 BigGAN residual block을 모두 사용한 핑크색 곡선이 가장 효과가 좋았다.
다음으로, AdaGN (Adaptive Group Norm) layer를 추가하여 실험해보기도 하였다. 이는 특정 클래스에 Groupnorm을 적용하고, time과 class embedding을 추가하는 레이어이다.

여기서 ys와 yb는 timestep과 class embedding의 linear projection이다.

AdaGN은 Ho et al.에서 사용한 Addition + GroupNorm보다 FID의 개선을 보였다.
Section 3 : Classifier Guidance
본 논문에서는 noisy image에 대해 training된 classifier의 gradient를 이용하여, 디퓨전 모델에 guidance를 주는 방법을 활용한다.

위와 같은 classifier에 대해,

이 gradient를 이용하여 guidance를 주는 것이다.

구체적으로, x_t에서 x_t-1 을 샘플링하는 단계에서, x_t에서 예측된 평균 mu에다가 classifier gradient의 상수배를 더해주는 방식이다. 저자들은 이러한 scaling을 여러 상수로 실험해 보았는데, s=1일 때 평균 50% 정도의 확률로 원하는 클래스가 generation 되었다고 한다. s값을 늘리면 100%에 가까운 확률로 원하는 클래스를 만들 수 있다.

왼쪽은 s=1, 오른쪽은 s=10을 주고 웰시코기 이미지를 생성한 결과이다.

DDIM을 conditioning할 때는, noise prediction단계에서 gradient를 빼는 방식이다.
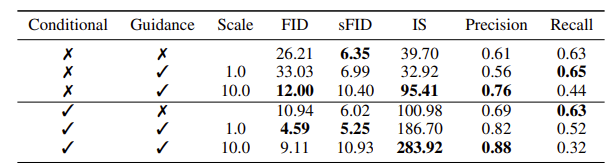
Classifier Guidance는 Recall을 희생하여 Precision을 높인다. 생성모델에서 Prec와 Rec은 실제 이미지 manifold를 ground truth로 하고, generated image manifold를 predicted로 하여 계산되는데, precision이 높아졌으므로 generated image 중 실제 manifold에 속하는 이미지가 늘어난 것이다.

이러한 분석을 다양한 s값에 대해, FID, IS 메트릭에도 적용해 보았다. s값이 늘어날수록 guidance가 커짐을 확인할 수 있다.
Results
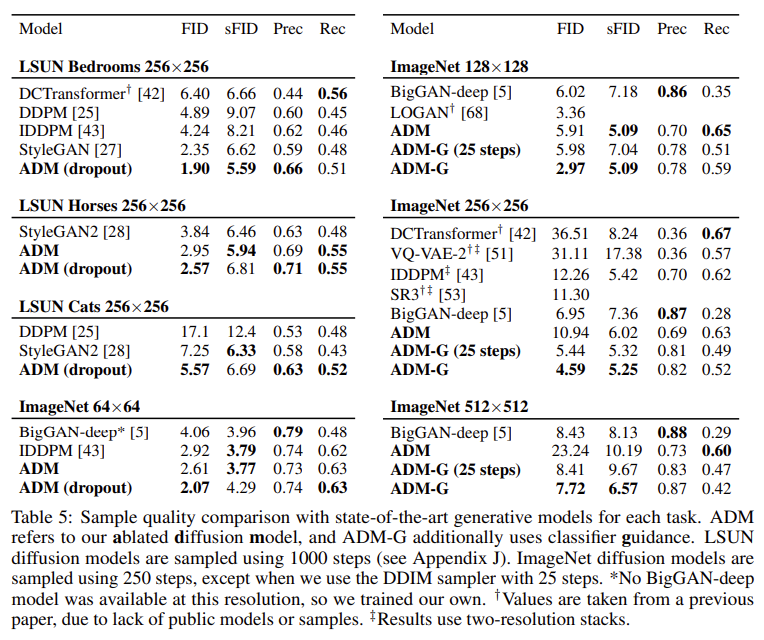
본 논문에서 소개한 ADM-U (Ablated Diffusion Models)와 ADM-G (guided)의 성능이다. 많은 데이터셋에서 생성 메트릭 SOTA를 달성한 것을 확인할 수 있다.
Future Works
디퓨전의 느린 샘플링은 여전히 문제로 작용한다. 따라서 샘플링을 가속하는 연구가 중요할 것이다. 또한, conditioning을 처음 시도한 논문인 만큼, CLIP 등의 vison-text model을 이용하면 text 로 guidance로 줄 수 있지 않을.... 까? 하면서 논문이 끝난다.
'머신러닝&딥러닝 > 생성모델' 카테고리의 다른 글
| OpenAI Guided-diffusion 코드분석 Part 1: Gaussian Diffusion 유틸 (0) | 2024.08.18 |
|---|---|
| VAE latent는 어떻게 생겼을까? (feat. PCA) (0) | 2024.08.14 |
| DDIM 논문 리뷰 - 샘플링 가속과 consistency (1) | 2024.08.14 |
| DDPM pytorch 코드분석 (0) | 2024.08.13 |
| AnoDDPM 논문 리뷰 (AnoDDPM: Anomaly Detection with Denoising Diffusion Probabilistic Models using Simplex Noise) (0) | 2024.08.06 |