2024. 4. 22. 20:46ㆍ머신러닝&딥러닝/CNN
CNN 모델은 20세기에 등장하여, 1990년대에 들어 폭발적으로 발전했다. 지난 번 리뷰한 1998년의 LeNet-5는 MNIST라는 손글씨 데이터 분류에서 당시 sota를 찍었던 모델인데, 손글씨 데이터셋은 분류할 항목이 숫자(0~9)밖에 없기 때문에 아주 쉬운 태스크이다.
https://cascade.tistory.com/40
[CNN] LeNet-5를 활용한 손글씨 인식 (Yann LeCun 1998 논문 리뷰)
패턴 인식은 실용성이 아주 높은 분야이다. 손글씨 인식을 대표로 하는 OCR(Optical Character Recognition)기술, 얼굴 인식, 생체정보 인식 등의 기술은 현재 널리 사용된다. 이러한 기술에 커다란 발전을
cascade.tistory.com
글자 인식, 그 중에서도 손글씨의 인식은 OCR(Optical Character Recognition) 분야의 기초 중에 기초다. 하지만, CNN은 이 이후로 점차 발전하여 글씨 인식을 넘어서 복잡한 이미지 안에 어떤 사물이 있는지 구별할 수 있는 수준까지 이르게 된다. 이것이 2010년대 초반 이야기이다. AlexNet은 이러한 이미지 분류(image classification)과 CNN의 발전과정에 큰 획을 그은 모델이다. 2012년 발표된 이 논문(1)은 2024년 4월 현재 128,178회 인용되었으며, 당시 최대의 이미지 데이터셋인 ImageNet의 분류 태스크에서 압도적인 sota를 찍었다.
본 포스팅에서는 이 논문을 리뷰해 볼 예정이다.
(1) A.Krizhevsky et al., ImageNet Classification with Deep Convolutional Neural Networks, NeuroIPS, 2012
Introduction
컴퓨터를 이용한 사물 인식 작업의 정확도를 높이려면 어떻게 해야 할까? 데이터셋을 더 크게 만들고, 모델을 더 강력하게 만들며, overfitting을 방지할 더 좋은 알고리즘을 쓰면 된다.
하지만 2012년 전까지의 모델들은 그 capacity가 너무 작아, 충분히 큰 데이터셋을 학습하지 못하고 작은 데이터셋만 학습할 수 있었다. 대표적인 것이 위에서 설명한 MNIST 데이터셋이다. (MNIST란? : https://cascade.tistory.com/51) MNIST처럼 "쉬운" 데이터셋은 거의 인간 수준에 육박하는 정도로 classification 작업이 가능(<0.3%) 해졌다.
그것보다는 조금 더 어려운 NORG, Caltech-101/256, CIFAR 10/100 같은 데이터셋도 상당한 수준으로 분류가 가능해졌다. 이 데이터셋은 10,000장 단위의 이미지를 포함하고 있는데, 본 논문에서 다루고자 하는 데이터셋의 크기는 이를 한참 초월한다. 100,000장 단위의 이미지를 가지는 LabelMe나, 1500만장에 육박하는 ImageNet 데이터셋에 대해 얘기해볼 것이다.
ImageNet 같은 데이터셋을 학습하려면, 모델 너비 및 깊이를 모두 늘려야 하기에 연산 처리가 까다롭다. 따라서 이들을 돌리는 데 GPU(GTX 580, 3GB짜리로 5~6일 트레이닝)를 사용할 것이다. (GPU로 트레이닝한 모델 중 어느 것이 최초인지는 잘 모르겠다..) 논문의 저자들은 AlexNet이라는 별명을 가진 모델로, 이 ImageNet 데이터 분류 작업을 매우 우수하게 해 내어, 이미지 분류 대회인 ILSVRC-2010, ILSVRC-2012에서 좋은 성과를 거두었다. 이 모델에는 5개의 convolution layer와 3개의 FC layer가 들어간다.
ImageNet 데이터셋에 대한 소개
ImageNet은 1500만장의 이미지를 묶어놓은 데이터셋이며, 총 22,000개의 카테고리로 분류된다. 모두 인터넷에서 긁어 온 이미지들이며, 라벨링은 아마존의 크라우드 소싱 툴을 이용했다. 2010년부터 이 데이터셋을 이용한 이미지 분류 대회가 있어 왔으며, 이를 ILSVRC(ImageNet Large-Scate Visual Recognition Challenge)라고 한다. 여기서는 Train : Valid : Test를 1,200,000 : 50,000 : 150,000 으로 쪼개 쓴다. AlexNet은 ILSVRC-2010년 대회에 나온 데이터셋으로 학습하고, ILSVRC-2012에 출전하였다.
ImageNet에서는 두 가지 error rate를 채점 기준으로 한다. 첫째로, top-1 error는 모델이 가장 높은 확률로 예상한 카테고리에 대한 error rate이다. 둘째로, top-5 error는 모델이 확률이 높을 것으로 생각한 다섯 가지 카테고리에 대한 error rate이다. 즉, 예측한 5개 중에 정답이 있으면 정답, 없으면 오답인 셈이다.
또한 ImageNet에는 여러 가지 해상도의 이미지가 주어진다. 반면 CNN의 특성 상 input의 크기가 일정한 이미지만을 넣어야 한다. 따라서, AlexNet은 이미지를 down-sampling하여 모두 256 x 256으로 고정했다. 다른 전처리는 모든 이미지의 mean activity를 빼준 것 말고는 하지 않았다. (모든 이미지의 픽셀 평균값을 빼주어 정규화했다는 의미인듯..)
AlexNet의 아키텍쳐
아키텍처를 살펴보기에 앞서, AlexNet이 (거의) 최초로 도입한 몇 가지 기술들이 있다.
- ReLU Nonlinearity
- 여러 개의 GPU 사용
- Local Response Normalization
- Overlapping Pooling
하나씩 살펴보고 가자.
ReLU Nonlinearity
기억한다면, 지난 번 LeNet-5 모델에서는 activation function으로 하이퍼탄젠트 함수를 썼다. 그보다 더 옛날로 가서, Multi-Layered Perceptron을 다뤘을 때(https://cascade.tistory.com/36)는 아래와 같은 시그모이드 함수를 썼다.

이런 함수를 "saturating nonlinearity" 라고 하는데, 이들의 output 값은 반드시 특정 범위 안에 있게 된다. (즉, 상한 하한이 있다는 말이다.) 이렇게 되면, non-saturating nonlinearity인 함수보다 수렴이 늦어질 수 있다. 따라서 본 모델에서는 activation function으로 "ReLU(Rectified Linear Unit)"라는 함수를 쓸 것이다.

실제로 위와 같이 CIFAR-10 데이터셋으로 실험해본 결과, ReLU 함수로 된 신경망(실선)이 tanh 함수로 된 신경망(점선)보다 빠르게 수렴했다.
여러 개의 GPU 사용
120만 개의 데이터셋은 하나의 GTX 580 GPU에 못 올라간다. (메모리가 3기가밖에 안함..) 그래서 두 개의 GPU를 parallel하게 연결해서, 커널을 두 GPU에 반반씩 놓아서 학습시키고, 특정 층에서만 이 두 GPU가 커뮤니케이션하도록 만들었다!! 예를 들어, 위 그림에서 보면 layer 2에 있는 커널들은 앞선 layer의 절반에서만 input을 받지만, layer 3은 layer 2 전체에서 받는다. 커뮤니케이션하는 이유는, cross validation하기 위함인데, 컴퓨터가 수용 가능한 수준의 연산으로 튜닝하는 것도 중요하다. 이러한 아키텍처는 top-1 error와 top-5 error를 각각 1.7%, 1.2% 줄여 주는 것으로 나타났다. 또한, 시간 효율성 측면에서도 두 개의 GPU를 쓰는 편이 좋다.
Local Response Normalization
ReLU 함수는 saturation이 안 되어 있다. 따라서, 엄청나게 큰 인풋 값이 들어오면 그것이 그대로 다음 뉴런에 전달되어 다른 뉴런의 값에 상관없이 다음 뉴런에 큰 영향을 줄 수 있다. 이를 방지하기 위해, (x, y)의 위치에서 kernel i 를 적용한 a값을 아래와 같이 정규화하여 b값을 도출한다. 여기서 사용한 상수 k, n, 알파, 베타는 validation set을 이용해서 조절해 사용했다.
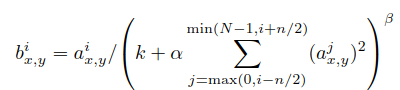
티스토리 Taegu님(https://taeguu.tistory.com/29) 에 따르면 이러한 Local Response Normalization은 신경생리학에서 말하는 lateral inhibition의 개념과 유사하다고 한다. 아래의 Herman Grid를 볼 때, 주시하고 있지 않은 흰 선 사이사이에 검은 반점이 보이는 현상이다. 한 영역 내의 신경세포는 인터뉴런에 의해 억제하는 구조로 되어 있기 때문에 일어나는 현상이다.

이러한 Local Response Normalization을 통해 CIFAR-10에서 실험해본 결과, 4-layer CNN의 error rate가 13%에서 11%로 떨어졌다.
Overlapping Pooling
기존의 모델에서 일반적으로 pooling을 할 때, pooling하는 필터 사이즈와 step을 일치시켜 중복되는 영역이 없도록 했다. 반면 이 모델에서는 step을 필터 사이즈보다 작게 만들어 겹치는 부분이 생기도록 overlapping pooling 시켜주었다.

이러한 방법으로 top-1과 top-5 error rate를 각각0.4%, 0.3% 낮췄다.
이제, 모델의 전체적인 모양을 살펴 보자.
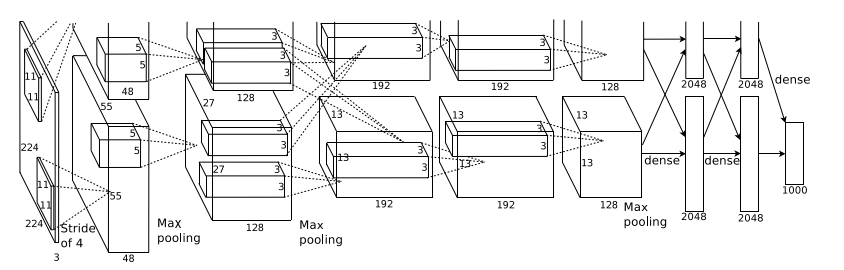
AlexNet은 위와 같이 5개의 convolution layer와 3개의 FC layer로 되어 있다. 마지막 FC layer는 1000개의 클래스로 연결되는 softmax 함수에 들어간다.
2, 4, 5번 convolution layer는 이전 층의 절반에서만 input을 받아오고, 3번 convolution layer는 이전 층 전체에서 input을 받아온다. 왜 이렇게 구성했는지는 아래의 "여러 개의 GPU 사용" 항목을 참고하길. Response Normalization은 1, 2번째 층에 들어갔고(아래의 "local response normalization" 항목 참고), Max pooling은 1, 2, 5번째 층에 들어갔다. ReLU는 모든 convolution / FC layer에 들어갔다.
인풋 사이즈는 224 x 224 x 3이다. 이는 11 x 11 x 3짜리 커널 96개(stride = 4) 와 연결된다. 두 번째 convolution layer는 5 x 5 x 48짜리 커널 256개로 되어 있다. 3, 4, 5번째 층은 normalization이나 intervening pooling 없이 구성되었다. Layer 3에는 3 x 3 x 256짜리 커널 384개, Layer 4에는 3 x 3 x 192짜리 커널 384개, Layer 5에는 3 x 3 x 192짜리 커널 256개가 들어간다. FC layer에는 각각 4,096개의 뉴런이 들어간다.
Overfitting 방지
이렇게 하여 총 6,000만 개 파라미터를 가진 AlexNet을 완성했다. 데이터셋이 아무리 커도, overfitting 문제는 발생하기 마련인데, 이 논문에서는 아래 방법으로 overfitting을 방지했다.
Data Augmentation
Label을 변화시키지 않는 transformation을 적용해서 인위적으로 데이터셋을 증강할 수 있다. 첫째로, 대칭과 평행이동이다. 원래 이미지 사이즈는 256 x 256 인데, 이를 인풋 사이즈인 224 x 224에 맞게 랜덤하게 뽑고 좌우 방향으로 대칭까지 시켜 한 원본 이미지에서 총 2048장의 새로운 이미지를 만들 수 있었다.
두 번째로, RGB 값에 PCA를 하여 변화를 주는 것이다. 구체적으로는 아래와 같이 RGB 픽셀 값에 대한 공분산 행렬(covariance matrix)를 계산하고, pi, lambda_i 를 각각 eigenvalue와 eigenvector로 갖도록 하여 아래와 같은 값을 각 픽셀에 더해 주었다.

이는 top-1 error rate를 1%까지 떨어뜨렸다.
Dropout
Dropout은 0.5의 확률로 은닉층의 뉴런의 output을 무조건 0으로 만들고 backpropagation도 안 하게 만드는 방법이다. 이러면 input이 들어올 때마다 다른 architecture에 의해 샘플링되기 때문에, overfitting을 방지할 수 있다. Test 할 때는 모든 뉴런을 켜는데, 대신 output 값에 모두 0.5씩을 곱해준다. 본 모델에서는 처음 두 FC layer에 dropout을 적용했다.
학습
학습은 SGD 옵티마이저, batch size 128, momemtum 0.9, weight decay 0.0005를 적용해 진행했다. weight는 아래 식으로 업데이트되는데, 지난 번 옵티마이저를 다룬 게시물(https://cascade.tistory.com/83)에서 살펴보았던 모멘텀이다.

초기 weight는 gaussian distribution에서 표준편차 = 0.01 을 두어 설정하였다. 또한 bias는 2, 4, 5번째 convolution, 그리고 FC layer에 넣었다. 모든 층에는 동일한 learning rate가 적용되고, 트레이닝 과정에서 직접 조작해 가며 했다. 구체적으로는 validation error가 안 떨어질 때마다 lr을 10씩 나눠 가면서 했다.
이렇게 하여 총 120만 장의 사진을 90 epoch 만큼 학습하였다.
결과

이 모델은 확률이 가장 높은 5개의 카테고리를 위와 같이 확률로 나타낸다.

ILSVRC-2010 대회에서 다른 모델들의 최고 성능과 비교한 본 모델의 성능이다. error rate가 확연히 낮은 걸 확인 가능하다.

ILSVRC-2012 대회에서의 결과이다. 별표된 모델은 2011년에 released된 ImageNet 버전으로 pretrained된 모델들이다. 이러한 우수한 결과는 convolution layer 하나가 제거되면 급감했으며, 이는 깊이가 학습에 아주 중요함을 시사한다.
저자들은 논문 말미에 궁극적으로 large, deep CNN이 나아가야 할 방향은 video에 적용하는 것이 아닐까 의문을 던진다. 컴퓨터비전이라는 분야가 나아가야 할 방향이 "컴퓨터에 눈을 달아주는 것"이라면, 저자들의 말이 어느 정도 일리가 있지 않을까?
'머신러닝&딥러닝 > CNN' 카테고리의 다른 글
| U-Net(O. Ronneberger 2015) 논문리뷰 및 pytorch 구현 (0) | 2024.06.25 |
|---|---|
| CNN에서 backpropagation이 이루어지는 원리 (0) | 2024.03.27 |
| pytorch를 이용한 LeNet-5(1998) 구현 (1) | 2024.03.15 |
| [CNN] LeNet-5를 활용한 손글씨 인식 (Yann LeCun 1998 논문 리뷰) (3) | 2024.02.26 |