2024. 2. 20. 03:40ㆍ머신러닝&딥러닝/인공신경망 기초

딥러닝 분야에는 다양한 아키텍처가 있다. CNN, RNN, Transformer 등으로 계보를 잇는 아키텍처들은 새로운 optimization 알고리즘이나 원리를 추가하면서 발전하지만, 모두 기본적인 학습 방식은 비슷하다. 이들이 사용하는 두 가지 기본적인 학습 방식은 Gradient descent(경사하강법)과 Backpropagation(역전파)이다. Backpropagation은 1960~1970년대부터 그 개념이 정립되어 왔지만, 이를 MLP(Multilayer Perceptron)의 효율적인 학습 방식으로 정착시켰다고 평가받는 유명한 논문(1)이 있다.
수학적 심리학/인지과학의 대가로 불리는 Rumelhart, "딥러닝의 아버지"이며 2023년 인공지능의 위험성을 알리며 구글을 퇴사했던 Geoffrey Hinton, 그리고 컴퓨터과학자 Williams의 공동 집필로 작성된 이 논문은 2024년 2월 19일 현재 무려 36,876회 인용되었다. 본 포스팅에서는 이 논문을 분석하여 Gradient descent와 Backpropagation의 원리에 대해 살펴보고자 한다.
(1) Rumelhart, D., Hinton, G. & Williams, R. Learning representations by back-propagating errors. Nature 323, 533–536 (1986).
Gradient descent
이 논문에 직접적으로 포함된 내용은 아니지만 이해해 도움을 주기 위해 Gradient descent를 간단하게 짚고 넘어가 보자.

Gradient descent는 loss function의 최솟값을 갖도록 하는 매개변수를 찾는 알고리즘이다. "내리막길은 앞으로 걸어가고, 오르막길은 반대로 걸어가야 더 낮은 곳으로 갈 수 있다" 라는 직관적으로 당연한 원리를 따르는 이 알고리즘은 수학적으로 나타내면 아래와 같다.

loss function의 미분값이 양수라면, w 값을 줄이고, 음수라면 w값을 늘리면서 local minimum을 찾는 방식이다. 만약 w값을 갱신했는데도 이전의 w값과 변화가 없다면, 최솟값을 찾았다고 생각하는 것이다. 이때 alpha 값은 learning rate 라고 한다. 모든 인공지능의 학습에는 다음의 이유로 적당한 learning rate를 찾는 것이 중요하다.
- 너무 큰 learning rate는 매개변수 w가 극소에서 수렴하지 않고, 발산(overshooting)하게 만들어 버릴 수도 있다.
- 너무 작은 learning rate는 학습을 매우 여러 번 해야 수렴하므로 비효율적이다.
그러나, gradient descent 방식에서 찾는 최솟값은 global minimum이 아닌 local minimum이므로, 적당한 초기 파라미터 설정을 해야 global minimum에 도달할 수 있다.
Multilayer Perceptron(MLP)구조
Backpropagation은 가중치를 반복적으로 갱신하면서 목표 결과치(desired output vector)와 실제 결과치(actual output vector)의 차이를 줄이는 방식으로 수행된다.

먼저 이 학습 방식이 적용되는 단일 퍼셉트론의 구조를 살펴보자. 퍼셉트론에 입력되는 Input vector는 y1, y2, ... yi의 input unit으로 구성되며, 이들은 개별 노드가 되어 입력된 후 wj1, wj2, ... wji의 가중치와 곱해져 xj라는 total input을 만든다.

이 total input (xj)는 활성화 함수(activation function)을 거쳐 output (yi)를 만드는데, 활성화함수는 모델에 따라 다양한 종류가 적용된다.

활성화 함수가 되기 위한 조건은, "bounded derivative"를 가져야 한다는 것이다. 즉, 도함수가 발산해서는 안 되고, 상한과 하한을 가져야 한다. 이러한 활성화 함수는 선형적인 input 과정에 비선형성을 추가하여 output을 만드는 역할을 한다. 본 논문에서 사용된 활성화함수는 아래와 같은 Sigmoid 함수이다.

본 논문에서는 input unit을 아래로, output unit을 위로 놓는 층위를 설정하여 특정한 수의 중간층(intermediate layer)을 그 사이에 끼우는 다층 퍼셉트론(MLP) 형태를 구상하였다. 우리가 보고자 하는 layer에는 j개의 퍼셉트론이 모여 있는데, 이 layer에 속한 하나의 퍼셉트론에 대하여 위에서 설명한 계산 과정을 거쳐 output unit (yj) 으로 만든 것이 output vector y이다. 즉, 실제로는 아래의 layer에 있던 i개의 퍼셉트론에서 나온 output vector의 unit (y1, y2, ..., yi)을 연산하고, 이를 합쳐 j개의 unit을 가진 output vector를 만드는 것이다.

Backpropagation이란?
우리의 목표는, 특정 input vector에 대하여, actual output vector가 정답(desired output vector)과 일치하거나 일치하다고 할 수 있을 정도로 가까운 가중치 세트를 찾는 것이다. 즉, actual output vector와 desired output vector의 차이를 에러 E라고 정의할 때, 이를 최소화하는 것이다. E는 아래와 같이 정의된다.

여기서 c는 input-output 쌍의 수 (학습 과정이라면 정답이 label된 데이터셋의 수)가 되고, j는 output unit에 대한 index이다. y는 actual state, d는 desired state를 의미한다. 여기서 E는 가중치 wji들에 대한 매개변수(parameter)로 표현되므로, E는 각 wji에 대해 편미분된다.
여기까지의 계산은 정방향과 역방향의 두 가지 방향으로 계산될 수 있다.
| 구분 | 내용 | 방향 |
| 정방향 | 각 layer에 입력된 input vector의 unit들을 식 (1)을 통해 가중치에 곱하고 더하여 output vector를 만드는 것 | 낮은 layer-> 높은 layer |
| 역방향 | output unit에 대한 E의 변화율을 통해 가중치의 변화율을 역산하는 것 | 높은 layer-> 낮은 layer |
이 중 역방향 계산을 통해 가중치를 갱신하는 것이 backpropagation이다.
Backpropagation의 계산
Backpropagation은 output unit을 이용하여 가중치의 변화율을 역산하는 것이기 때문에, E를 yj에 대해 편미분하자. 특정한 case 하나만 계산한다고 했을 때, 식 (2)에서 c를 없앨 수 있다. E를 yj에 대해 편미분한 결과는
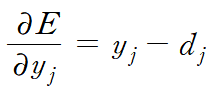
이다. E를 xj에 대해 편미분한 결과를 얻기 위해 chain rule을 적용하자.
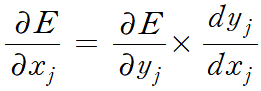
xj와 yj는 sigmoid 관계로 정의되므로, sigmoid 방정식의 양변을 미분하여 dyj/dxj 를 계산할 수 있다.

이는 total input을 의미하는 xj와 output unit의 하나인 yj의 변화가 E에 어떤 변화를 줄 수 있는지를 나타낸 관계식이다. 그런데, 여기서 xj는 가중치 wj1, wj2, ..., wji의 선형 결합이자, 더 낮은 계층에서 넘어온 output unit인 y1, y2, ..., yi의 선형 결합이다. 따라서, 먼저 이 관계식을 가중치 wji에 대한 편미분 형태로 고칠 수 있다. (이때 식 (1)을 편미분한 결과가 들어갔다)
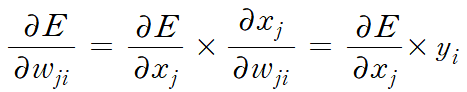
다음으로 output unit인 yi에 대한 편미분 형태로 고쳐 보자.

이 식을 각 j (=1, 2, ...)에 대하여 더하면, 현재 layer에 input으로 들어오는 yi라는 (바로 아래 layer의) output unit이 각 j에 대하여 연산되는 것을 모두 고려할 수 있다.
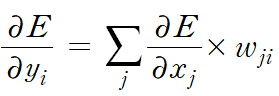
따라서, 우리는 다음과 같은 관계식을 얻는다.
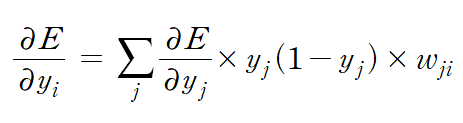
식 (4)가 시사하는 점은, yj를 output으로 갖는 layer에 대한 에러 함수 정보로, 그 아래에 있는 layer에 있는 에러 함수 정보를 얻을 수 있다는 점이다. 즉, 귀납적으로 보았을 때, MLP의 출력층에서 나온 output vector로 E를 편미분한 결과를 통해, input vector로 E를 편미분한 결과를 "역방향으로" 계산할 수 있다. 그리고 이 과정에서 식(3)을 사용하면, 각 매개변수에 관한 다음의 정보 또한 얻을 수 있다.

즉, 각 input-output case를 연산하고, 위 식을 이용하여 가중치를 수정할 수 있다는 것이다. 가중치를 수정하는 과정에서 상술한 Gradient descent 알고리즘이 적용된다.

Backpropagation이 가지는 의의
본 논문에서는 이 gradient descent의 장단점을 서술한다. 먼저, 장점은 단순하다는 것이다. 따라서 parallel hardware에 implementation하여 사용할 수 있다. 하지만, 다른 몇몇 알고리즘에 의해 그리 빠르게 수렴하지는 않는다. 이를 해결하기 위해, gradient에 따라 속도를 조절하는 가속 알고리즘(acceleration method)를 쓰기도 한다.

저자들은 이러한 다층 퍼셉트론의 훈련 방식이 실제 뇌와는 다르지만, 다양한 분류 모델에 적용될 수 있을 것으로 예측하였다. 실제로, 앞서 설명하였듯, 본 논문에서 소개된 backpropagation은 현재 AI 학습의 기본 원리로 자리잡았다.
'머신러닝&딥러닝 > 인공신경망 기초' 카테고리의 다른 글
| L2 regularization과 weight decay (1) | 2024.08.19 |
|---|---|
| [머신러닝] 옵티마이저(optimizer)의 종류 (1) | 2024.04.12 |
| Perceptron Convergence Theorem과 그 증명 (1) | 2024.02.19 |