2024. 4. 2. 21:02ㆍ머신러닝&딥러닝/RNN
바닷가 앞 의자에 사과가 하나 놓여 있다. 배경에는 폭죽놀이가 한창이다. 사람의 눈으로 사과를 주시하고 있을 때, 우리는 배경에 어떤 모양의 폭죽이 터지는지와 상관없이 사과라는 개체에 시선을 집중할 수 있다.

Attention이라는 알고리즘이 나오기 전의 컴퓨터는 이러한 시선 집중을 할 수 없었다. 원근감, 사물 등의 개념을 그저 픽셀의 RGB 값으로만 인식했었기 때문에, 이미지에서 집중에서 보아야 할 사물이 무엇인지 알지 못했던 것이다. Attention은 컴퓨터가 특정 context에 "주의 집중"할 수 있도록 만들어준 알고리즘이며, 생성형 AI, 인공지능 번역, 자연어 처리, 영상 처리 등 다양한 분야에 사용된다. 또한 오늘날 인공지능 모델들의 아주 중요한 구성요소인 transformer의 기초가 된다.
본 포스팅에서는 Attention이라는 개념을 처음으로 도입한 기계 번역 모델인 RNNsearch를 발표한 2014년 논문(1)을 리뷰해볼 예정이다. 여담으로, 세계 인공지능 석학이자 자랑스러운 한국인이신 조경현 교수님께서 쓰셨던 논문이다. 인용수는 2024년 4월 기준 15,431회이다.
(1) D.Bahdanau et al., Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
Introduction
본 논문은 인공지능 번역의 새로운 모델 RNNsearch를 제시한다. 기존의 모델들은 대부분 encoder-decoder 구조 기반(seq2seq 등)이었는데, 입력 벡터와 출력 벡터가 모두 고정된 길이였기 때문에 latent space에서 정보 압축이 일어날수록 손실이 발생한다는 단점이 있었다.
이를 보완하기 위해 도입된 Attention은, 번역된 문장에서의 특정 위치에 따라, 입력 문장의 각 단어에 서로 다른 가중치를 두어 단어에 따른 중요도를 차등 부여한다.
Background
기존의 번역 모델
x라는 입력 문장이 올바르게 번역된 문장 y가 있다고 하자. x 들의 분포, y들의 분포가 있을 때, 우리가 원하는 것은 x가 주어졌을 때 올바른 번역 y가 나올 조건부 확률 p(y | x)를 최대화하는 y를 찾는 것이다. 일반적으로 NMT(Neural Machine Translation, 신경망 기계 번역) 분야에서는 이 조건부 확률 분포를 인공지능 모델을 이용하여 최적화한다.
NMT에서 사용되던 기존의 대표적인 모델은 RNN Encoder-Decoder 모델(Cho 2014, Suskever 2014)이다. RNN(특히 LSTM) 을 기반으로 하는 이 모델은 입력 벡터열 x = {x1, x2, ...} 를 encoder가 읽어 벡터 c를 아래와 같이 만든다. 이때, h_t는 RNN의 시간 t에서의 hidden state이다.
이때, 벡터 c는 맥락을 나타내는 context vector이며, Decoder는 (1) context vector, (2) 이전 단어 정보를 활용하여 다음 단어를 예측하는 식으로 번역을 한다. 그러면 전체 p(y)의 분포는 번역문의 각 단어의 확률분포를 곱하여 아래와 같이 얻을 수 있다.
Learning to Align and Translate
본 논문에서는 NMT를 위한 새로운 아키텍처를 제안하는데, 이는 아래와 같이 구성된다.
- Encoder: 쌍방향 RNN(BiRNN) 으로 구성
- Decoder: "원문을 찾아보는 행위"를 모사하는 디코더
Decoder
번역 문장의 각 단어를 찾는 조건부 확률 식을 아래와 같이 다시 쓸 수 있다.
이때, si는 시간 i에 대한 RNN의 hidden state이며, 아래와 같이 이전의 hidden state, 이전 단어, 그리고 context vector ci에 따라 결정된다.
위에서 소개했던 RNN encoder-decoder 모델과 다른 점은, 각 yi를 결정하는 확률이 모든 y에 대해 동일한 context vector c 하나에 대해 결정되는 것이 아니라, 각 i마다 서로 다른 context vector를 가진다는 점이다.
이를 그림으로 나타내면 위와 같이 된다. 입력 문장 x1, x2, ...은 각각의 위치에서의 context vector를 만들어내기 위해 annotation (h_i)이라는 것을 만든다. Annotation은 후반에서 더 자세히 설명하겠지만, 아래 두 가지 성질을 갖는다.
- 입력 문장에 대한 전체 정보를 담고 있다.
- i번째 단어(x_i)에 대한 강조점이 들어가 있다.
annotation으로 context vector를 만드는 식은 아래와 같다.
a_ij는 무엇일까? 이는 가중치인데, 아래와 같은 allignment model로 계산된다.
e_ij의 식을 보면, j번째의 annotation과 i-1번째의 번역 결과가 들어가 있다. 즉, e값은 하나 전의 번역 결과와 현재의 annotation에 영향을 받아 결정되고, 이 e값으로 a_ij가 결정된다. 다시 말해, 입력 문장의 위치 j와 출력 문장에서의 위치 i가 잘 맞아 떨어지는지 보는 것이다. 이제, 인공 신경망을 alignment model a를 학습하도록 훈련하면 된다.
Encoder
인코더는 쌍방향 RNN(Bidirectional RNN, BiRNN)으로 구성된다. 이는 forward, backward RNN 으로 나뉘며,
forward RNN은 문장을 앞에서 뒤로 읽으며 forward hidden state를 만들고, backward RNN은 문장을 뒤에서 앞으로 읽으며 backward hidden state를 만든다.
Experiment
BLEU score: Blingual Evaluation Understudy로, 사람이 한 번역과 기계가 한 번역의 유사도를 측정하여 점수화한 것
본 아키텍처는 2014 ACL 워크샵 에서 주어진 문장 데이터셋( Translation Task - ACL 2014 Ninth Workshop on Statistical Machine Translation (statmt.org)) 을 이용하여 검증하고, Cho et al.의 RNN Encoder-Decoder 모델과 성능을 비교하였다. 문장 데이터셋을 토큰화한 후 언어마다 가장 빈번하게 사용된 30,000개의 어휘를 뽑아 모델을 트레이닝하였다.
결과적으로, 모든 경우에 RNNsearch는 RNNencdec의 성능을 능가하였다. 또한, 모르는 단어(UNK)가 없었을 때는 기존의 번역 시스템인 Moses를 능가하는 성능을 보였다.
문장의 길이가 길어질수록 RNNenc, RNNsearch-30의 성능은 감소했지만, RNNsearch-50의 성능은 크게 감소하지 않았다.
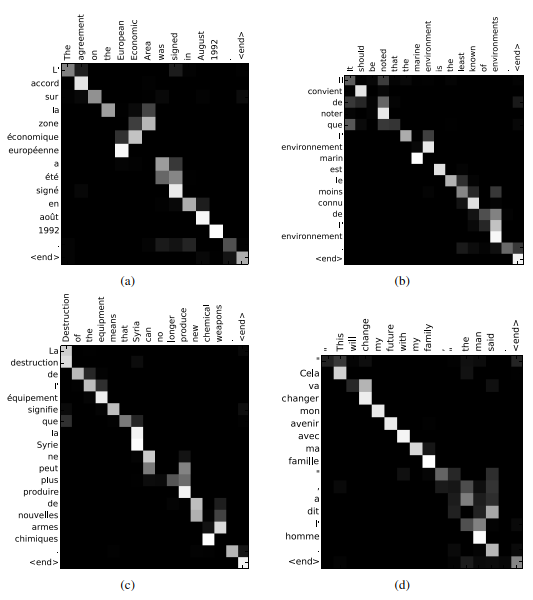
위 그림은 RNNsearch-50으로 번역을 했을 때, 언어별로 alignment가 발생한 단어 조합이다. x축은 영어, y축은 프랑스어를 나타낸다.
'머신러닝&딥러닝 > RNN' 카테고리의 다른 글
| RNN cell 구조와 BPTT(Backpropagation through time) (0) | 2024.06.27 |
|---|