2024. 3. 22. 19:34ㆍ머신러닝&딥러닝/생성모델
DDPM이란?
DDPM(Denosing Diffusion Probabilistic Model)은 발전된 형태의 diffusion 생성모델로, 이미지에 gaussian noise 를 조금씩 첨가하여 완전한 noise image로 만들어지는 과정 (q) 을 학습하여, 완전한 noise 이미지에서 noise를 걷어(p) 이미지를 생성한다.
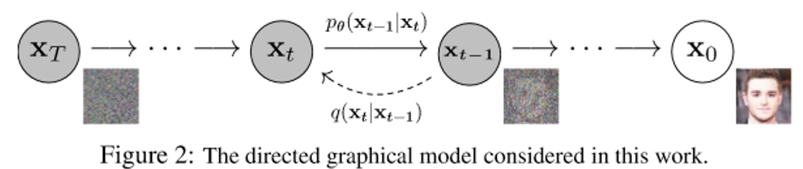
원본 이미지 x0에 노이즈를 한 단계씩 추가하여 완전한 noise 이미지로 바뀐 것을 xt라고 하자. DDPM은 아래와 같이 두 과정으로 진행된다.
- Forward process: x0-> xt로 만드는 noising 과정
- Reverse process: xt-> x0으로 만드는 denoising 과정
이미지 생성을 위해 필요한 것은 reverse process이다. 노이즈를 추가하는 과정에 대한 분포인 q를 이용하여 노이즈를 걷을 때의 분포인 p를 추정한다. 이때 중요한 전제가 들어가는데, 이미지에 노이즈가 추가되어 xt가 되는 과정은 Hidden Markov Chain이라는 것이다. Hidden Markov Chain이란, 연속한 상태에 대하여 현재 상태가 오직 이전 상태에만 영향을 받는 구조이다. 즉, x_t는 x_t-1에만 영향을 받아 그 이전 단계는 계산에 포함할 필요가 없다.

위 그림은 DDPM을 이용하여 X-ray image를 생성하는 reverse process의 예시이다.

DDPM의 수학적 원리
2020년에 Jonathan Ho, Ajay Jain, Pieter Abbeel에 의해 개발된 DDPM(1)은 VAE와 같이 변분 추론(Variational Inference)을 이용한다.
1. Gaussian Diffusion
t-1번째 이미지에서 t번째 이미지로 노이즈를 추가하는 과정 q는 아래와 같다. beta값은 variance scheduler이다. beta = 1이라면 x_t-1 항이 사라지기 때문에 t번째 이미지가 오직 noise에 의해서만 표현될 것이다. 반면, beta = 0이라면 노이즈가 포함되지 않을 것이다.

분포 q는 hidden markov chain이기 때문에, q(x_t | x_0)은 연속한 두 q를 아래와 같이 곱하여 계산할 수 있다.
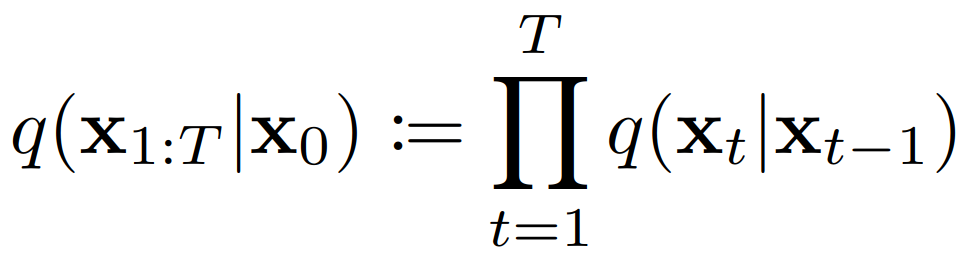
우리가 원하는 분포 p (노이즈-> 이미지)를 이 q를 이용하여 추정할 것이다. 즉, p는 x_t에서 시작하여 x_0까지 이어지는 chain으로 나타낼 수 있으며, 아래 수식의 오른쪽 부분의 mu (평균)과 sigma(표준편차)가 우리가 추정해야 할 값들이다.
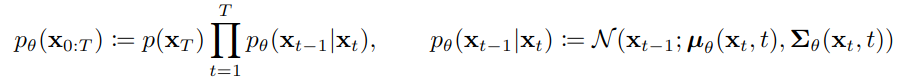
q를 어떻게 p로 추정할 수 있을까? 이는 지난 논문 리뷰(https://cascade.tistory.com/47)인 VAE에서 다루었던 ELBO 식을 이용할 수 있다.
Variational Auto-Encoder (Kingma, 2013 논문 리뷰)
VAE(Variational Auto-Encoder)는 생성형 AI의 역사에 중요한 획을 그은 모델로, 입력 데이터의 확률 분포를 학습하여 새로운 데이터를 생성하는 모델이다. 이 모델은 2013년 D.P.Kingma와 Max Welling의 논문(1)
cascade.tistory.com
간단하게 복습을 해보자면, 아래 식이 성립한다.
ELBO = PLL - KLD
(PLL: positive log likelihood, KLD: kullback-leibler divergence)
이때 KLD는 항상 0 이상으므로 ELBO는 PLL의 하한선이다. 추정의 목표는 ELBO를 최대화하여, PLL을 높여 근사를 더 잘 하는 것이다.
즉, ELBO <= PLL 이 성립한다. 이 식에 양변에 마이너스를 취하면, NLL <= -ELBO = L이 된다. L값은 위에서 설명한 hidden markov chain의 성질에 의해 아래의 등호와 같이 전개할 수 있다.

이 L값을 잘 전개하면 아래와 같이 나타낼 수 있다.

이 L값은 "수학적 귀납법"의 원리와 같이, x_t로 x_t-1을 예측할 수 있다면 x_0도 예측할 수 있다는 원리를 가진다. 이 식으로 KL Divergence를 통해 forward process의 posterior ( q(xt|x0) 등)을 reverse process와 직접 비교할 수 있게 되기 때문에, L을 objective function이라고 부른다. 이때 q는 gaussian noise를 통해 아래와 같이 표현 가능하다. alpha는 1-beta를 바꾼 것뿐이다.
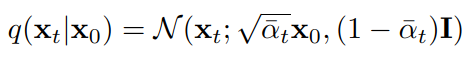
따라서, 이 q를 이용해서 식 (1)의 mu와 sigma를 아래와 같이 추정할 수 있다.

Diffusion
위의 objective function인 L에는 세 개의 항, L_t, L_t-1, L_0이 들어간다. 먼저, L_t의 경우 forward process에서는 beta 값이 학습되지 않고 상수로 고정하기 때문에, L_t 자체를 상수취급해도 된다. 둘째로, L_t-1의 경우 아래와 같은 과정을 거친다.
- q(x_t-1 | x_t) 계산
- p(x_t-1 | x_t) 계산
- sigma 값 추정 (p의 표준편차)
- mu값 추정 (p의 평균)
4번 과정은 아래와 같이 계산할 수 있는데, 자세한 증명이 궁금하다면 논문을 참고하길 바란다.

이를 이용하면, p(x_t-1 | x_t)를 추정한 것이 되므로 x_t를 이용하여 x_t-1을 sampling 할 수 있게 되는 것이다. 이들을 잘 조합하여 L_t-1을 아래와 같이 계산할 수 있다. 마찬가지로 자세한 증명이 궁금하다면 논문을 참고하길 바란다.
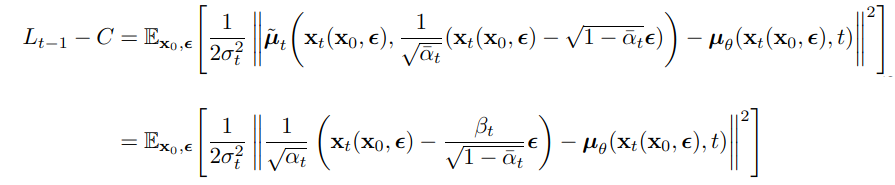
DDPM으로 이미지 생성
아래는 원 논문에서 CIFAR10 데이터셋을 학습하여 생성(progressive generation)한 이미지이다. 기존 생성AI sota인 각종 GAN들과 Inception score, FID score (생성된 데이터가 식별자를 얼마나 잘 속이는지 판단하는 척도)를 비교해본 결과, Inception score는 StyleGAN2 + ADA가 가장 우수했지만, FID는 DDPM이 가장 우수했다.

아래는 CelebA-HQ 데이터셋을 이용하여 interpolation한 이미지이다.

Interpolation은 두 이미지의 latent vector x0과 x0'를 아래와 같은 식으로 latent space에서 섞어 만든다.
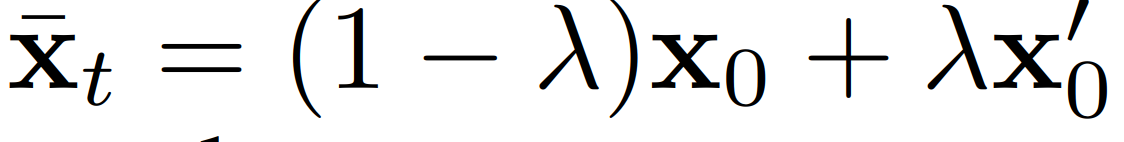
'머신러닝&딥러닝 > 생성모델' 카테고리의 다른 글
| RePaint : DDPM Inpainting 리뷰 (A.Lugmayr 2022 논문 리뷰) (3) | 2024.05.17 |
|---|---|
| 생성 모델로 만든 이미지의 평가 방법 (S.Azizi 2023 논문 리뷰) (1) | 2024.04.15 |
| Variational Auto-Encoder (Kingma, 2013 논문 리뷰) (0) | 2024.03.06 |
| Cross Entropy와 쿨백-라이블러 발산(KL-Divergence) (6) | 2024.03.05 |
| ML(Maximum Likelihood), MAP(Maximum A Posteriori) 추정 (0) | 2024.03.04 |