2024. 7. 29. 19:49ㆍ머신러닝&딥러닝/생성모델
디퓨전 모델의 아이디어인 열역학적 확산이 최초로 제안된 것은 2015년(https://arxiv.org/abs/1503.03585)이며 디퓨전의 원조격으로 unconditional하게 random noise에서 이미지를 합성할 수 있는 DDPM이 나온 것은 2020년이다.
DDPM은 t번째 timestep에서 noise가 얼만큼 포함되어 있는지를 CNN 기반의 U-Net으로 예측한다. 하지만, classificaion/segmentation에서 CNN 기반 모델의 sota를 ViT 기반 모델 (시초는 https://arxiv.org/abs/2010.11929) 들이 갈아치우고 있는 상황에서, denoising에도 ViT를 써볼 수 있으리라 예상할 수 있다. U-ViT는 ViT를 U-Net이랑 비슷한 형태 (down/upsample, skip connection)로 만들어 denoising에 쓸 수 있도록 만든 아키텍처이다.
본 포스팅에서는 U-ViT가 등장한 논문인 All are Worth Words: A ViT Backbone for Diffusion Models(https://arxiv.org/pdf/2209.12152) 를 리뷰하고자 한다.
한줄요약 : DM에서 U-Net based 아키텍처를 U-ViT로 바꾼 페이퍼로, U-ViT를 uncond, class-cond image generation, text to image generation에 대해 evaluation함
Introduction
DM 소개
DM의 시초
- noneqilibrium thermodynamics 2015 논문
- DDPM 2020 논문
- score based generative 2020논문
최신 DM은 high quality image generation에 쓴다
- Diffusion models beat GANs~ 2021 논문
- Cascaded diffusion 2022 논문
- LDM 2022 논문
Text conditioning으로 text to image도 한다
- clip latents 2022 논문
- Imagen 2022 논문
image to image도 한다
- llvr 2021
- sdedit 2021
- egsde 2022
video generation도 한다
- Imagen video 2022
- VDM 2022
Speech synthesis
- Wavegrad 2020
- Diffwave 2020
3D synthesis
- Dreamfusion
디퓨전 백본 소개
디퓨전의 노이즈 예측은 U-Net으로 해왔었는데, ViT가 CNN based model을 앞서고 있는 상황에서는 이런 질문을 해볼 수 있다. U-Net denoising은 diffusion에 필수적인가???
그래서 본 논문에서는 U-ViT를 제안한다. patchified image뿐 아니라 Time, condition 모두 tokenization해서 트랜스포머에 넣을 것이다.
또한 이 U-ViT에 특징적인 새로운 구조는 아래와 같다.
- long skip connections: U-Net에서 영감을 받음
- 3x3 conv block을 output layer 앞에 추가해서 visual quality 향상
검증은 아래 세 task에 대해 수행했다.
- Uncond gen
- class-cond gen
- text-to-image gen
결론부터 말하자면 모든 U-Net 기반 비슷한 크기의 DM보다 우수한 성능을 보였고, U-ViT기반 LDM이나 text-to-image는 가히 압도적이라고 할 수 있었다. (ImageNet, MS-COCO 등 테스트)
Background
디퓨전 수식에 대한 간략한 소개
- 노이즈 스케줄링
- 알파베타 잡는 법
- 디퓨전 loss
ViT
- image is worth 16 16 words (2020)을 읽어라.
Method

U-ViT는 U-Net과 마찬가지로 noise prediction net이다. 위 그림에서 볼 수 있듯 time(t), condition(c)를 임베딩한다. 또한 downsampling upsampling 모두 transformer block 기반으로 이루어지고, 사이사이에는 U-Net과 비슷하게 long skip connection이 들어간다. 이는 low level feature를 살리는 기능을 한다.
또한 output layer 직전의 3 x 3 conv는 트랜스포머에 의해 형성된 artifact를 제거하는 기능을 한다(왜?). 즉 visual quality를 향상시킨다.
디테일한 구현
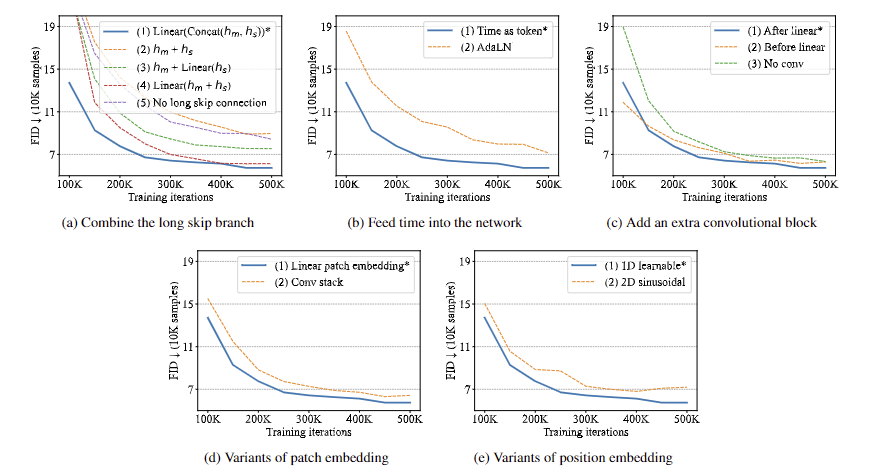
- long skip branch를 어떻게 합칠래? 기존 방법론에서도 여러가지를 썼었지만, (1) concat (2) direct adding (3) linear proj → adding (4) adding → linear proj 정도가 있을 것이다. 그리고 대조군으로 (5) 안 쓰는 경우 를 설정하고 다섯 가지로 구현하고 실험해 봤다. 위 결과에서 보다시피 (1) concat 이 결과가 가장 좋았다.
- Time을 어떻게 임베딩할래? 이건 두 가지 방법이 있는데 (1) tokenization (2) AdaLN 이 있다. AdaLN은 조금 생소할 수도 있는데 Adaptive LayerNorm을 말한다. 즉 layer norm까지 끝나고 time embedding의 linear projection (ys, yb)가 왼쪽 수식과 같이 합쳐지는 것이다. AdaLN(h, y) = ysLayerNorm(h) +yb (시간 변수로 normalization parameter를 결정하는 거라고 생각하면 쉽다.) 두 개를 비교해 보니 위 결과처럼 (1) tokenization의 성능이 더 좋았다.
- 마지막 3x3 conv 은 어떻게 사용할까? 모델 전체 그림을 보면 마지막 transformer layer 이후에 linear projection이 들어간다. (1) linear projection 이후에 3x3 conv를 쓰는 방법이랑 (2) 3x3 conv를 쓰고 linear proj를 하는 두 가지 방법을 생각할 수 있다. 대조군으로 (3) 안 쓰는 경우까지 실험해본 결과 proj 이후에 3x3 conv를 하는 것의 효과가 가장 좋았다.
- Patch & Position embedding Patch embedding과 positional embedding 방식은 각각 두 가지씩 실험해봤다. (1) Patch를 바로 Linear proj 해서 임베딩하는 경우, (2) 3x3 conv block를 스택하고 1x1 conv로 매핑해서 linear하게 만드는 경우 두 가지 중에서는 첫 번째 (1) 바로 linear proj 하는 방법의 성능이 더 좋았다. 또한, Position은 1D와 2D sinusoidal을 테스트해봤는데, 1D가 효과가 더 좋았다.
Depth, Width, Patch Size가 주는 효과
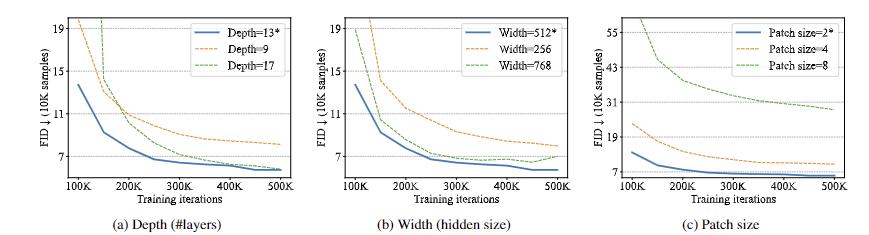
- CIFAR-10으로 테스트 시 depth가 9→13이 되었을 때 성능이 좋아졌다. 다만, 17로 늘렸을 때는 좋아지지 않았다.
- Hidden width를 256, 512, 768 로 바꿔가며 실험했을 때 512가 가장 성능이 좋았다.
- Patch Size는 2, 4, 8 중 2가 가장 좋았다. 패치가 작을 때 성능이 좋다는 것에 주의하라고 한다.
Related Works
Diffusion에서의 Transformer
- GenViT라는 아키텍처가 2022년 나왔으나 본 모델과의 차이는 skip connection이 없고 3x3 conv가 없어 크기가 더 작다는 점이다.
- VQ-Diffusion 논문도 읽어 봐라.
Diffusion에서의 U-Net
- NLL loss를 쓰는 score based model의 경우 디퓨전의 등장 이전에도 U-Net을 써 왔었다.
- 디퓨전 원조 논문(DDPM, 2020)에서는 U-Net에 Group Norm을 섞어서 썼다.
- Diffusion models beat GANs(CG 원조 논문, 2021)에서는 improved residual block과 cross attention을 썼다.
- Improved DDPM(2021)에서는 U-Net에 Multihead attention을 섞어서 썼다.
Diffusion의 역사
- sampling 속도의 진화
- training method의 진화
- generation control (CG, CFG, text guidance, prompting…)의 발전
Experiments

Uncond. generation
- CIFAR10, CelebA, ImageNet 64x64에서는 훨씬 가벼운 ViT기반 모델인 GenViT보다 FID가 크게 개선되었으나, U-Net 기반 diffusion에 비해서는 별로 좋은 점을 모르겠다.
- 256, 512 ImageNet에서의 성능은 U-Net 기반에 비해 좋은 성능을 보였다.
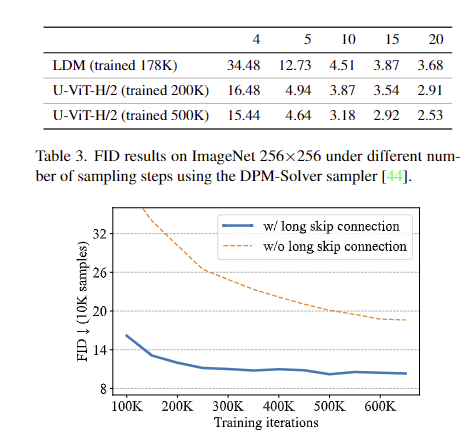
Class Cond. generation
LDM보다 성능이 좋았고, 트레이닝 셋 크기에 따른 비교도 진행했다. 그리고 long skip connection이 있을 때 성능이 훨씬 좋았다.
Text Cond. generation

설명은 생략한다.

'머신러닝&딥러닝 > 생성모델' 카테고리의 다른 글
| DDPM pytorch 코드분석 (0) | 2024.08.13 |
|---|---|
| AnoDDPM 논문 리뷰 (AnoDDPM: Anomaly Detection with Denoising Diffusion Probabilistic Models using Simplex Noise) (0) | 2024.08.06 |
| RePaint : DDPM Inpainting 리뷰 (A.Lugmayr 2022 논문 리뷰) (3) | 2024.05.17 |
| 생성 모델로 만든 이미지의 평가 방법 (S.Azizi 2023 논문 리뷰) (1) | 2024.04.15 |
| DDPM을 통한 이미지 생성 및 보간 (J. Ho 2020 논문 리뷰) (1) | 2024.03.22 |