2024. 4. 8. 18:07ㆍCS/자료구조
* 본 글은 [윤성우의 열혈 자료구조 - C언어를 이용한 자료구조 학습서] 를 바탕으로 작성하였습니다.
열혈 자료구조 교재에서는 이제까지 리스트, 스택, 큐의 자료구조를 다루었다. 이들은 모두 선형적인 자료구조인 반면, 본 포스팅에서 정리할 트리는 비선형 자료구조이다. 트리는 컴퓨터 디렉토리, 가계도, 조직도, 의사결정 트리 등의 계층적 정보를 표현할 수 있는 자료구조이다.
트리 용어

- 노드(Node): 트리의 구성 요소, 위 그림에서는 2, 7, 5 등의 숫자에 해당
- 간선(Edge): 노드와 노드를 연결하는 선
- 루트 노드(Root node): 최상위의 노드, 위 그림에서는 2
- 단말 노드(Terminal node): 아래에 다른 노드가 연결되지 않은 노드, 위 그림에서는 2, 5, 11, 4 / Leaf Node 라고도 부름
- 내부 노드(Internal node): 단말 노드를 제외한 모든 노드 / Nonterminal Node 라고도 부름
- 부모 노드(Parent node) / 자식 노드(Child node): 트리 구조의 위아래로 1칸 차이로 연결된 두 노드의 관계, 위 그림에서는 4와 9
- 형제 노드(Sibling node): 부모 노드가 같은 노드들, 위 그림에서는 5와 11
서브 트리(Sub Tree) , 이진 트리(Binary Tree)

서브 트리란 큰 트리 안에 속하는 작은 트리를 말한다. 위에서 보았던 트리는 오른쪽 서브 트리와 왼쪽 서브 트리로 나뉘고, 그 아래에는 더 작은 서브 트리들이 있다.
이를 이용해, 이진 트리를 아래 두 조건으로 재귀적으로 정의할 수 있다.
- 루트 노드를 중심으로 두 개의 서브 트리로 나누어진다.
- 두 개의 나누어진 서브 트리도 모두 이진 트리이다.
이때, 이진 트리의 정의에서 공집합 노드도 서브 트리로 간주한다. 따라서 위 그림에 나온 트리도 이진 트리이다. 즉, 직관적으로 각 노드에서 2개 이하의 edge가 나오면 되는 것이다.
포화 이진 트리(Full binary tree), 완전 이진 트리(Complete binary tree)
트리의 root node를 level 0으로 생각하고, 자식 노드 하나씩 내려갈수록 level이 하나씩 늘어나는 것으로 생각할 수 있다. 또한, 가장 높은 level을 트리의 높이로 정의할 수 있다.

- 포화 이진 트리: 모든 level이 꽉 차 있는 이진 트리
- 완전 이진 트리: 모든 level이 차 있지는 않지만, 빈틈없이 node가 채워진 상태. 즉 terminal node를 제외하고는 공집합 노드가 있어서는 안 된다.
따라서, 위의 트리는 level 3이 꽉 차 있지 않기 때문에 포화 이진 트리는 아니지만, 완전 이진 트리는 맞다.
이진 트리의 구현
이진 트리는 스택, 큐와 마찬가지로 배열로도, 연결 리스트로도 구현이 가능하다. 배열로 구현하는 것의 장점은 탐색을 빠르게 할 수 있다는 점이지만, 이진 트리는 일반적으로 배열보다는 연결 리스트로 구현한다. (단, 완전 이진 트리의 일종인 heap은 배열을 기반으로 구현한다고 한다.) 그리고 노드는 아래와 같은 형태로 만든다.

먼저 이진트리의 헤더 파일 BinaryTree.h을 분석해 보자. BTreeNode 구조체는 data와, 왼쪽/오른쪽 노드를 참조하는 포인터 변수를 가지고 있다.
#ifndef __BINARY_TREE_H__
#define __BINARY_TREE_H__
typedef int BTData;
typedef struct _bTreeNode
{
BTData data;
struct _bTreeNode * left;
struct _bTreeNode * right;
} BTreeNode;
BTreeNode * MakeBTreeNode(void);
BTData GetData(BTreeNode * bt);
void SetData(BTreeNode * bt, BTData data);
BTreeNode * GetLeftSubTree(BTreeNode * bt);
BTreeNode * GetRightSubTree(BTreeNode * bt);
void MakeLeftSubTree(BTreeNode * main, BTreeNode * sub);
void MakeRightSubTree(BTreeNode * main, BTreeNode * sub);
#endif
- MakeBTreeNode: 노드의 생성
- GetData: 노드에 저장된 데이터 반환
- SetData: 노드에 데이터 저장
- GetLeftSubTree / GetRightSubTree : 왼/오른쪽 서브트리의 주소값 반환
- MakeLeftSubTree / MakeRightSubTree: 두 트리의 주소를 인자로 받아, 첫 번째 트리의 왼쪽/오른쪽 자식 노드로 두 번째 노드를 연결

예를 들어, 위와 같은 이진 트리를 만들고자 한다면, 아래와 같이 함수를 호출할 수 있다.
#include <stdio.h>
#include "BinaryTree.h"
int main(){
BTreeNode * nd_A = MakeBTreeNode();
BTreeNode * nd_B = MakeBTreeNode();
BTreeNode * nd_C = MakeBTreeNode();
MakeLeftSubTree(nd_A, nd_B);
MakeRightSubTree(nd_A, nd_C);
}
앞선 연결 리스트, 스택, 큐와의 다른 점은, 함수를 사용하여 데이터를 저장하면 자료구조가 "알아서" 만들어졌지만, 트리는 그렇지 않다는 점이다. 이제 헤더 파일에 나온 각 함수를 구현해보자.
BTreeNode * MakeBTNode(void){
BTreeNode * newNode = (BTreeNode *) malloc(sizeof(BTreeNode));
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
BTData GetData(BTreeNode * bt){
return bt->data;
}
void SetData(BTreeNode * bt, BTData data){
bt->data = data;
}
BTreeNode * GetLeftSubTree(BTreeNode * bt){
return bt->left;
}
BTreeNode * GetRightSubTree(BTreeNode * bt){
return bt->right;
}
void MakeLeftSubTree(BTreeNode * main, BTreeNode * sub){
if(main->left != NULL) free(main->left);
main->left = sub;
}
void MakeRightSubTree(BTreeNode * main, BTreeNode * sub){
if(main->right != NULL) free(main->right);
main->right = sub;
}
나머지는 모두 뻔하게 구현하면 되지만, MakeLeftSubTree/MakeRightSubTree에서 만약 왼쪽/오른쪽 노드가 채워져 있다면 해당 노드를 free 해주는 작업을 꼭 넣어주어야 한다.
이진트리의 순회(Traversal)
이진트리의 순회란, 이진트리의 모든 노드에 접근하여 데이터에 필요한 작업을 하는 것을 말한다. 이진 트리의 순회 방법은 아래 세 가지이다.
- 전위 순회(Preorder Traversal): 루트 노드를 먼저 순회하는 방법
- 중위 순회(Inorder Traversal): 루트 노드를 중간에 순회하는 방법
- 후위 순회(Postorder Traversal): 루트 노드를 나중에 순회하는 방법
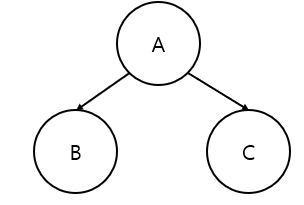
즉 위와 같은 이진 트리가 있을 때, A->B->C 순으로 순회하는 것이 전위 순회, B->A->C 순으로 순회하는 것이 중위 순회, B->C->A 순으로 순회하는 것이 후위 순회이다. 이러한 순회 알고리즘은 재귀적으로 구현된다. 즉, 위에 있는 B, C를 노드가 아니라 서브트리로 생각하는 것이다!! 예를 들어, 중위 순회는 아래와 같이 재귀적으로 구현할 수 있다. 재귀의 탈출 조건은, 공집합 노드를 만났을 때 return 하는 것이다.
void InorderTraverse(BTreeNode * bt)
{
if(bt == NULL)
return;
InorderTraverse(bt->left);
printf("%d \n", bt->data);
InorderTraverse(bt->right);
}
이때, 출력 이외의 다른 가능을 순회에 넣고 싶다면, 그 기능을 함수로 만들어 넣으면 된다. 예를 들어, 모든 노드에 1을 더하는 것, 2를 곱하는 것, 출력하는 것 등 다양한 작업을 할 수 있는데, 이를 Traverse 함수의 인자로 넣어 아래와 같이 구성하자.
InorderTraverse(bt->left, action);
action(bt->data);
InorderTraverse(bt->right, action);
이렇게 하면 action의 내용에 따라 노드 안 데이터에 가해지는 작용이 달라지게 된다.
'CS > 자료구조' 카테고리의 다른 글
| [열혈자료구조] 10강. 정렬(sorting) (1) (1) | 2024.04.16 |
|---|---|
| [열혈자료구조] 9강. 우선순위 큐(Priority Queue)와 힙(heap) (0) | 2024.04.09 |
| [열혈자료구조] 7강. 큐(queue) (0) | 2024.04.07 |
| [열혈자료구조] 6강. 스택(stack) (0) | 2024.04.05 |
| [열혈자료구조] 5강. 연결 리스트(Linked List) 3 - (2) (0) | 2024.04.02 |