2024. 4. 1. 02:00ㆍCS/자료구조
* 본 글은 [윤성우의 열혈 자료구조 - C언어를 이용한 자료구조 학습서] 를 바탕으로 작성하였습니다.
본 포스팅에서는 교재를 바탕으로 단순 연결 리스트의 ADT를 정의하고, 정렬 기능과 노드 삽입 기능을 구현해 보고자 한다.
정렬 기능의 추가
ADT는 구현 방식과 무관하며 기능만 포함되면 되기 때문에, 앞선 포스팅에서 다루었던 배열로 정의한 리스트(https://cascade.tistory.com/69)를 그대로 가져와 써도 된다. 대신, 정렬 기능만 추가해 보자.
1. 리스트의 생성
: 리스트의 주소 값을 인자로 전달하고 초기화한다.
void ListInit(List *plist);
2. 데이터의 저장
: 리스트에 데이터를 저장한다.
void LInsert(List * plist, LData data);
3. 첫 번째 데이터 참조
: 새로운 메모리를 잡고 리스트의 첫 데이터를 옮긴다. 성공 시 1, 실패 시 0를 반환한다.
int LFirst(List * plist, LData * pdata);
4. 다음 데이터 참조
: 참조된 데이터의 다음 데이터가 순서대로 pdata에 저장된다. 성공 시 1, 실패 시 0을 반환한다.
int LNext(List * plist, LData * pdata):
5. 마지막 반환 데이터 삭제
: LFirst 혹은 LNext 함수가 마지막으로 반환한 데이터를 삭제한다.
LData LRemove(List * plist);
6. 리스트 크기
: 리스트에 저장된 데이터 수를 반환한다.
int LCount(List * plist);
7. 리스트 정렬
: 특정 함수를 기준으로 리스트를 정렬한다.
void SetSortRule(List * plist, int (* comp ) (LData d1, LData d2));
또한, 이전 포스팅(https://cascade.tistory.com/72)에서는 머리(head)는 가만히 있고 꼬리(tail)에 새로운 데이터를 추가했었는데, 반대로 꼬리를 가만히 놔두고 머리에 새로운 데이터를 추가하는 것도 가능하며, 두 가지 방법에는 장단점이 존재한다. 본 교재에서는 tail을 유지하기 번거롭고, 리스트는 저장된 순서를 굳이 보존할 필요가 없으므로 노드를 머리에 추가하는 방법을 사용하였다.
| 머리에 추가 | 꼬리에 추가 | |
| 장점 | tail 포인터 변수가 불필요하다. | 저장된 순서가 유지된다. |
| 단점 | 저장된 순서가 유지되지 않는다. | tail 포인터 변수가 필요하다. |
정렬 함수
정렬 함수인 SetSortRule은 sorting하려는 리스트의 주소 값과 정렬 기준이 되는 함수를 인자로 받는다. 이때 int (*comp) (LData d1, LData d2)는 두 개의 LData 자료형을 받아 int를 반환하는 함수의 주소값 comp를 말한다. 예를 들어, 아래와 같은 비교 함수가 *comp가 될 수 있다.
int WhoIsPrecede(int d1, int d2)
{
if(d1 < d2)
return 0;
else
return 1;
}
즉, WhoIsPrecede에 두 데이터 D1, D2를 넣었을 때 0이 나온다면 D1이 head에 가까워야 하고, 1이 나온다면 D2가 head에 가까워야 한다.
더미 노드(Dummy Node)
이전 포스팅(https://cascade.tistory.com/72)에서 다루었던 연결 리스트의 구조로 돌아가 보자.

노드를 추가, 삭제, 조회할 때, 2 노드는 나머지와의 차이가 있는데, 데이터가 들어있는 노드가 아닌 head가 가리키고 있다는 점이다. 이는 여러 가지 불편함을 가져오므로, 아래와 같이 더미 노드(Dummy Node)를 추가하여 구현한다.
만약 새로운 노드를 head 쪽으로 추가해 간다면, tail은 불필요해지므로 삭제하였다. 또한 dummy node로 인해 첫 번째로 추가되는 노드가 dummy 이후의 두 번째 노드 역할을 하게 되므로 노드의 추가, 삭제, 조회 과정을 일관되게 수행할 수 있다. 더미 노드를 기반으로 리스트를 초기화를 할 때에는, 아래와 같이 plist-> head를 NULL이 아니라 더미 노드로 한다.
void ListInit(List * plist)
{
plist->head = (Node*)malloc(sizeof(Node));
plist->head->next = NULL;
plist->comp = NULL;
plist->numOfData = 0;
}
연결 리스트의 구조체
앞서 아래와 같이 Node 구조체를 구성하였다.
typedef struct _node
{
int data;
struct _node * next;
} Node;
이때, Node * head, Node * cur 와 같은 노드들은 절대로 전역 변수 혹은 main함수의 지역 변수로 설정하면 안 된다. 그 이유는 하나의 코드에서 여러 번의 배열을 정의할 수 있는데, 그럴 때마다 head1, head2,... 와 같은 식으로 새로 정의할 수는 없기 때문이다. 따라서, 아래와 같이 연결 리스트 자체의 구조체를 정의하는 것이 좋다.
typedef struct _linkedList
{
Node * head;
Node * cur;
Node * before;
int numOfData;
int (*comp)(LData d1, LData d2);
} LinkedList;
연결 리스트의 구성 요소로 head, cur가 들어가고, 데이터 수, 정렬 함수가 들어간다. before의 용도는 추후에 소개할 것이다.
노드 삽입
노드가 삽입될 때, 정렬 기준이 없다면 head에 삽입되고, 정렬 기준이 있다면 이에 근거하여 노드를 추가하도록 구현되었다. 즉, LInsert라는 전체 노드 삽입 함수에, 정렬 기준 comp의 유무에 따라 comp가 NULL이면 FInsert를, NULL이 아니면 SInsert를 호출하도록 했다.
void FInsert(List * plist, LData data)
{
Node * newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = plist->head->next;
plist->head->next = newNode;
(plist->numOfData)++;
}
void SInsert(List * plist, LData data)
{
Node * newNode = (Node*)malloc(sizeof(Node));
Node * pred = plist->head;
newNode->data = data;
while(pred->next != NULL &&
plist->comp(data, pred->next->data) != 0)
{
pred = pred->next;
}
newNode->next = pred->next;
pred->next = newNode;
(plist->numOfData)++;
}
void LInsert(List * plist, LData data)
{
if(plist->comp == NULL)
FInsert(plist, data);
else
SInsert(plist, data);
}
FInsert는 head 자리에 새로운 노드를 넣는 함수이므로, 원래 dummy 노드가 가리키던 노드를 새로운 노드가 가리키도록 하고, dummy는 새로운 노드를 가리키도록 코드를 작성한다.
또한 SInsert는 정렬 기준
노드의 조회
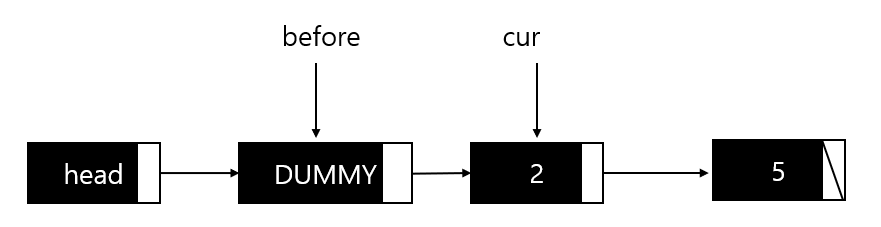
배열 리스트에서와 마찬가지로, LFirst와 LNext를 이용하여 노드의 데이터를 조회한다. 먼저, LFirst는 dummy가 NULL을 가리키면 FALSE를 반환하고, 그렇지 않으면 before가 dummy를, cur가 첫 번째 노드를 가리키도록 한다. 이처럼, before는 cur보다 하나 앞서는 노드를 가리키기 위한 노드이다.
int LFirst(List * plist, LData * pdata)
{
if(plist->head->next == NULL)
return FALSE;
plist->before = plist->head;
plist->cur = plist->head->next;
*pdata = plist->cur->data;
return TRUE;
}
LNext는 cur이 NULL이면 FALSE를 반환하고, NULL이 아니면 cur이 가리키고 있던 노드를 before에게 넘기고 cur는 그 다음 노드를 가리킨다.
int LNext(List * plist, LData * pdata)
{
if(plist->cur->next == NULL)
return FALSE;
plist->before = plist->cur;
plist->cur = plist->cur->next;
*pdata = plist->cur->data;
return TRUE;
}
노드의 삭제
LRemove는 배열 리스트와 마찬가지로, 바로 이전 LFirst 혹은 LNext로 반환한 데이터를 삭제한다. LRemove의 호출 직전 cur가 가리키고 있던 노드를 삭제하고, 삭제된 노드의 앞 노드는 삭제된 노드가 가리키던 노드를 연결한다. 또한, cur이 가리키는 노드가 하나 뒤로 밀려 before와 같아진다.
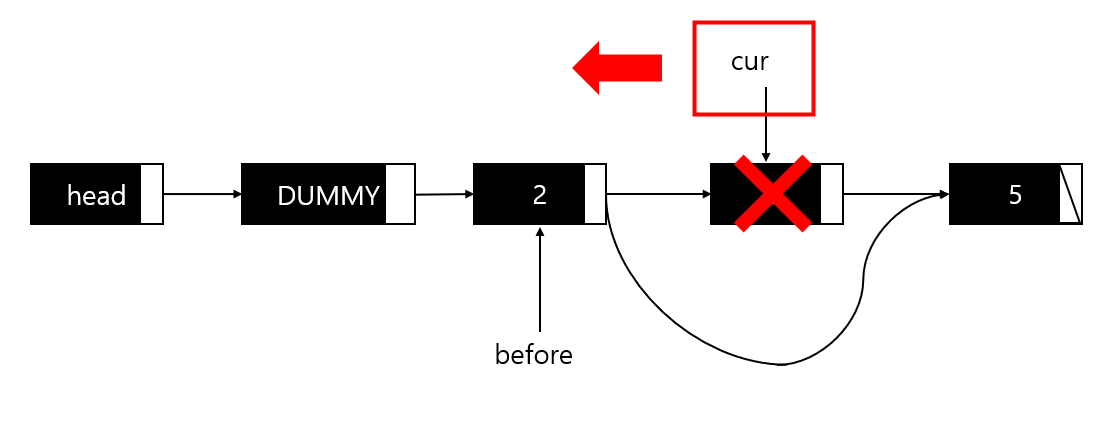
이러한 상황에서 before가 중요한데, 앞선 포스팅(https://cascade.tistory.com/72)의 delNode와 마찬가지로 삭제되는 노드 앞의 노드의 주소를 저장하는 역할을 하여 cur이 효율적으로 이를 전달받을 수 있도록 한다. 이는 코드로 아래와 같이 구현되었다.
LData LRemove(List * plist)
{
Node * rpos = plist->cur;
LData rdata = rpos->data;
plist->before->next = plist->cur->next;
plist->cur = plist->before;
free(rpos);
(plist->numOfData)--;
return rdata;
}
다음 포스팅에서는 연결 리스트의 다른 종류인 원형 연결 리스트와 양방향 연결 리스트에 대해 다룰 예정이다.
'CS > 자료구조' 카테고리의 다른 글
| [열혈자료구조] 5강. 연결 리스트(Linked List) 3 - (2) (0) | 2024.04.02 |
|---|---|
| [열혈자료구조] 5강. 연결 리스트(Linked List) 3 - (1) (0) | 2024.04.01 |
| [열혈자료구조] 4강. 연결 리스트(Linked List) 2 - (1) (0) | 2024.03.30 |
| [자작 예제] 유향선분 구조체를 저장하는 리스트 (0) | 2024.03.30 |
| [열혈자료구조] 3강. 연결 리스트(Linked List) 1 - (2) (0) | 2024.03.30 |