AI의 역사를 만든 전설적인 논문들

올해 하는 연구가 AI 관련인데, 이쪽 분야에 대해서는 딥러닝 선택교과 수업 하나 들은 거 말고 노베이스여서 대략적인 흐름을 잡아 보고자 survey를 진행해보기로 했다. 우리 연구에 직접적으로 크게 도움이 안 될 수는 있는데, 그래도 어떻게든 도메인 지식 & 거시적인 시야를 넓히는 데에는 도움이 되지 않을까 하여 시작하게 됐다. 본과 2학년 공부를 하면서 여유같은 건 없다 가 된다면 이 코너에 하나씩 올려 보도록 하겠다.
순환기 강의록 안 보냐고? 설 연휴 때 다 치움 ㅇㅇ
AI의 역사를 만들었다고 할 수 있는, 그야말로 "전설적인" 페이퍼를 몇 개 찾았다. 본 포스팅에서는 이 페이퍼들의 abstract부분만 찾아서 조금의 배경지식과 섞어, 나름 쉬운 언어로 정리해 보았다. 하지만 나 스스로도 이해가 안 된 부분도 많았기 때문에 그 부분은 어려운 언어를 그대로 두었다. 인용 수는 2024.02.12. 기준이다.
1. ImageNet Classification with Deep Convolutional Neural Networks (2012)
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, 인용 124,955회
해당 논문은 이미지 인식 대회에서 압도적인 성능을 거둔, deep CNN 모델의 아키텍처에 관한 내용이다. 저자 명단도 웅장한데, 제프리 힌튼(Geoffrey Hinton) 교수는 퍼셉트론과 역전파 이론(backpropagation)을 처음 증명하신 분이고, 그의 제자 일리야 서츠케버(Ilya Sutskever)는 알파고 등 프로젝트에 참여한 탑급 AI 엔지니어로 얼마 전 샘 알트만과의 OpenAI 분쟁을 했던 바로 그 사람이다.

CNN이란?

Convolutional Neural Network. 이미지 분석에 자주 이용되는 인공지능 모델. 여러 가지 크기의 필터(kernel)을 이용하여 합성곱 형태로 이미지의 특징을 추출하고, 이를 pooling 및 연산하여 결과를 도출한다.
논문의 요지
이미지 분석을 위한 labeled data를 천만 장 단위로 확보할 수 있는 ImageNet 데이터셋을 사용하였다. 이를 위해 CNN 모델의 용량과 성능을 압도적으로 개선하였다.

이 CNN 아키텍처는 5개의 convolution, 3개의 fc layer로 구성되었는데, 기존의 CNN과 다른 점이 몇 가지가 있다.
첫째로, 여러 대의 GPU를 사용하여, 커널 하나를 반반씩 서로 다른 GPU에 할당했다.
둘째로, 활성화함수로 sigmoid나 tanh를 쓰지 않고 ReLu를 써서 계산효율을 강화했다.
셋째로, overfitting을 줄이기 위한 방법(overlapping pooling)을 사용하였다.
이를 이용하여 학습 시간과 성능을 매우 개선하였고, 이미지넷에서 개최하는 이미지 인식 대회 ILSVRC에서 타 모델에 비해 압도적인 성능을 보여 주었다.
2. Auto-Encoding Variational Bayes (2013)
Diederik P. Kingma & Max Welling, 인용 32,941회
관련 내용을 잘 정리해 주신 Jinsol Kim(https://gaussian37.github.io/dl-concept-vae/)님 감사합니다.
Autoencoder란?
비지도 학습 알고리즘의 일종이다. 복잡한 정보 x(사진 등)를 "encoding"을 통해 간단한 latent variable(사진에 관한 함축적인 정보들)로 바꾸고, 이것을 "decoding"하여 결과 y를 출력한다. 이때 x와 y를 loss function으로 비교하여, 이를 최소화시키는 방향으로 학습을 한다. 학습이 완료된 상태에서의 encoder는 입력값 x에서 latent variable을 뽑아내는 역할을 할 수 있고, decoder는 latent variable로 x와 유사한 출력을 만들어낼 수 있다.

Variational Autoencoder(VAE)란?
Autoencoder 모델에서, 입력값 x로 만든 데이터셋 D = {x1, x2, x3, ...} 를 상상하자. 그러면 D의 각 원소에 encoder를 적용하여 만든 latent variable z1, z2, z3 ... 들의 분포 p(z)를 생각할 수 있다. 그러면 이 분포에서 임의로 하나의 랜덤값을 찍어서 decoder를 돌리면, D에 포함된 입력값들과 "유사한" 출력값을 얻을 수 있지 않을까?

여기서 핵심은, VAE에서는 latent variable의 분포 자체를 학습하여, 이 분포에서 sampling한 새로운 latent variable z*를 decode하여 전혀 새로운 결과 x*를 뽑아내는 데에 있다. 즉 encoder는 latent variable 그 자체를 만드는 것이 아니라, (gaussian 분포로 가정된) latent variable의 "분포"를 만드는 것이기 때문에, 그 분포의 "평균값"과 "표준편차"가 VAE model의 latent variable이 된다.

여기에서 "평균값"과 "표준편차"를 학습 가능하도록 만드는 과정에서 "reparametrization trick"이라는 게 쓰이는데, 이건 좀 어려우므로 패스.
논문의 요지
이 논문은 VAE라는 모델을 소개하는 논문으로, 모델의 핵심인 확률분포의 학습과 데이터의 생성이 수학적으로 어떻게 가능한지를 보여준다. Reparametrization trick, ELBO 등의 개념을 공부해야 할 것 같다.
3. Generative Adversarial Nets (2014)
Ian J. Goodfellow et al., 인용 65,037회
AI를 잘 몰라도 한번쯤 들어봤을 만한 제 얘깁니다 모델인 GAN을 소개한 전설적인 논문이다.
관련 내용을 잘 정리해 주신 PseudoLab(https://pseudo-lab.github.io/Tutorial-Book/chapters/GAN/Ch1-Introduction.html)님 감사합니다.
GAN 이란?

GAN은 Generative Adversarial Network의 약자이다. 여기서는 두 개의 네트워크 G(Generator)와 D(Discriminator)가 등장한다. G는 새로운 분포를 생성하는 역할을 한다. D는 생성된 분포가 "진짜"인지 "가짜"인지 판별하는 역할을 한다. GAN은 G와 D가 "적대적"으로 계속 학습하며, 진짜 분포에 가까운 데이터셋을 생성하는 것이 목표이다. PseudoLab 님의 설명에 따르면 G는 화폐 위조범이고 D는 경찰인데, 화폐 위조범은 경찰을 속이는 데 성공한 데이터를 계속 입력받고, 경찰은 화폐 위조범에게 속은 데이터를 계속 입력받아 학습하는 구조이다.
논문의 요지
이 논문은 GAN 모델을 창시한 논문이다. 저자 Ian Goodfellow는 GAN의 발명가로 알려져 있으며, 구글 브레인과 OpenAI에서 researcher로 근무했다.
4. Deep Residual Learning for Image Recognition (2015)
Microsoft Research team(Kaiming He et al.), 인용 199,687회 ㅎㄷㄷ
20만회 인용될 정도로 전설적인, "ResNet"이라는 알고리즘이 등장한 논문이다. 관련 내용을 잘 정리해 주신 onlybox 우진(https://velog.io/@woojinn8/CNN-Networks-4.-ResNet)님 감사합니다.
ResNet 이란?
ResNet은 마이크로소프트에서 2015년 발표한 일종의 CNN 네트워크이다. CNN은 layer의 수가 늘어날수록 수준높은 특징을 추출할 수 있고 정확한 결과를 도출할 수 있지만, 학습하는 데 어려움이 생긴다. 또한 overfitting 문제가 생길 수 있는데, ResNet 논문에서는 더 정확해야 할 깊은 층 네트워크(56-layer)가 얕은 층 네트워크(20-layer)보다 성능이 떨어지는 것을 보여 주었다. 이러한 현상을 해결하기 위해, ResNet에서는 Deep Residual Learning이라는 학습 방식을 만들었다.
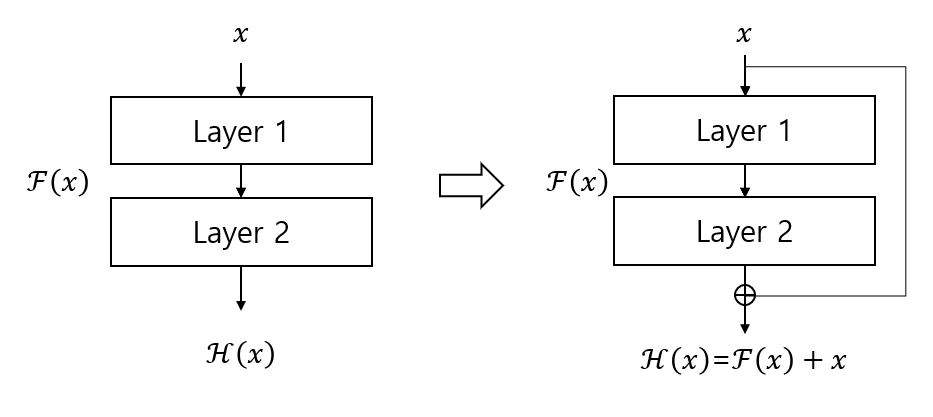
Deep Residual Learning이란?
입력 x를 layer에 넣어 출력된 값이 목표값 y에 근접하도록 하는 것이 기존 딥러닝 모델이라면, deep residual learning에서는 입력값과 출력값의 차이, 즉 residual을 mapping하도록 한다. ResNet 논문에서는 이러한 방식이 깊은 층의 성능 저하 현상을 막을 수 있음을 보여주었다. Deep Residual Learning의 핵심적인 구조는 shortcut connection인데, 레이어를 연속적으로 연결하는 것이 아니라 하나 이상 스킵해서 연결하는 구조이다.
5. Attention is All You Need (2017)
Google Brain team(Ashish Vaswani et al.), 인용 108,423회
본 논문의 공동 저자들이 구글 퇴사 후 창업한 회사들(cohere, essential.ai, character.ai 등) 의 누적 가치가 40억 달러에 이른다고 한다. 이 논문이 파급력이 컸던 이유는, 트랜스포머라는 구조를 처음으로 발표했기 때문이다. 이 논문 발표 이후, 트랜스포머만을 전문적으로 다루는 비즈니스인 Hugging Face가 생겨났다.

RNN이란?
트랜스포머 직전에 많이 사용되던 RNN(Recurrent neural network)은, 시계열 데이터 처리를 위한 모델이다. RNN의 가장 중요한 특징은 이름처럼 재귀적(recursive)하다는 것이다. 은닉층 h에 데이터 x가 들어왔을 때, 여기의 결과값을 출력층으로도 보내지만 다음 연산을 할 때 다시 은닉층의 입력값의 일부로도 보내는 것이다. 출력값이 다음 입력값으로 사용되기 위해서는 기억이 필요하므로 이 노드를 memory cell이라고도 한다.

RNN에는 LSTM, GRU 등의 모델이 있으며, 병렬처리가 어려워, 학습 속도가 느리다는 단점이 있다.
트랜스포머란?
RNN의 병렬처리 문제를 해결하여, 문장 구조와 같이 RNN에 적합하던 데이터를 훨씬 빠르고 좋은 성능으로 학습할 수 있도록 만든 것이 트랜스포머이다. 아키텍처는 아래와 같이 크게 Positional Encoding, Multi-Head Attention, FFN으로 이루어져 있다.
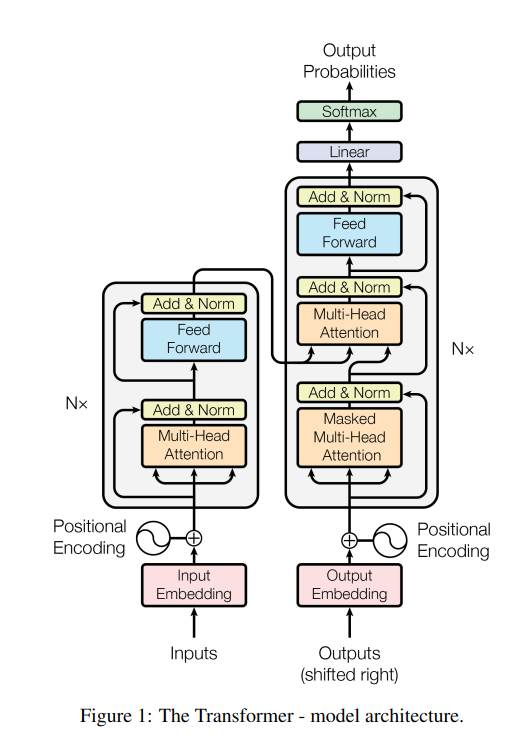
트랜스포머를 기반으로 하여, BERT와 GPT-3 등 NLP 모델들과 AlphaFold2가 만들어졌다.
이상 AI계에 큰 획을 그은 다섯 편의 논문을 살펴보았다.
Oselt